Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Global performance was improved through careful buffering and code optimization.
Allowed return types for methods stereotyped sql_update_operation are now void, boolean, and int. The return value of the underlying JdbcTemplate.update call will be translated appropriately.
PK_MODEL can now be used as an alternative to the PK_ENTITIES / PK_BUSINESS_OBJECT stereotypes.
The STEP_COMMAND_LINE stereotype can be used to launch external tools (such as command line scripts) from a step.
The path to the script and, if needed, script parameters (space-separated) must be provided through substitution properties.
The bean stereotype is now available to define simple classes (owning only getters, setters and attribute) used to exchange data inside the service layer. Those are a lightweight alternative to transient-stereotyped entity/BO couples.
The getters/setters creation wizard was updated accordingly.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Syntax coloring for comments have been restored.
The SET UP BY verb do not halt transmodeling anymore.
PERFORM X TIMES is now properly transmodeled as a loop.
VALUE ZERO is now properly modernized in LEVEL 88 context.
Commas in VALUE context are not interpreted as floats anymore, excepted if DECIMAL-POINT IS COMMA is present.
When using the file type detection and renaming feature of the reverse COBOL project creation wizard, the
.ddland.datextensions are now left as is.File type detection as been improved; binary files are not renamed as copybooks (
.cpy) anymore.
More variants of the COPY REPLACING are now supported.
Replacements leading to lines wider than 72 columns are now properly parsed.
Copybooks whose last line is not EOL-terminated are now supported.
More variants of READ, PERFORM, MULTIPLY and EVALUATE verbs are now supported.
More PIC variants are parsed.
StringUtils.isBlankis now generated instead ofReverseUtils.isSpace.When transmodeling a program containing
PROCEDURE DIVISIONstatements not contained in a section or paragraph, they are collected in a simulated[Program Name]_MAINparagraph.
The service creation wizard is now robust with respect to homonymous UML objects stored in the same package.
Setting the
ftpEnabledproperty is not required to generate sort steps anymore. ThesortEnabledproperty has been added for this purpose.A
recordLengthtag was added to theSORT_STEPstereotype in order to specify the length of input file records, when they are not delimited by anLFcharacter.A list of input files can now be specified to the sort tasklet by separating them by a comma or semicolon.
A
FILE_OPERATION_STEPis now available. When applied to aPK_STEPactivity, its functionality is specified by themodetag, which can take the following values:copy: files copy,delete: files deletion,merge: files merge,merge_copy: files merge (overwriting target file if it exists),reset: empty an existing file, or create a new empty file.
Files to process are specified by the
targets(mandatory) andsourcesproperties, using the Spring resources syntax competed by wildcards if needed. Multiple patterns can be separated by commas or semicolons.
Sonar warnings have been taken into account in code generation.
Javadoc on generated code and tools classes have been improved.
Use of fully qualified names for classes has been limited in generated code.
A
useSonarproperty was added to the SpringBatch workflow. It will trigger the addition of the sonar plugin to the parentPOM.A
useMavenAdditionalPluginsproperty has been added to the workflow. It is required for proper packaging of generated code with Maven (usingmvn:package).Any value of the language field of opaque actions different from “bags” is now ignored and lead to opaque content inclusion in the generated code. This works around a behavior of MagicDraw Properties Editor, which may set this field to “English” instead of leaving it empty.
The postprocessor can now have a return type of
int,BooleanorString.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
In some scenario the DataFlow view could disable selections in the COBOL annotations editor. This is fixed.
Slowdowns of the annotation editor when using BLU AGE in a remote (RDP) environment have been fixed.
Navigation in previously visited locations in legacy code (using the
Ctrl+Click/Alt+Left/Alt+Rightshortcuts) cannot be hampered by transmodeling or some views display anymore.
Explicit (literal)
CALLs between COBOL programs can now be followed usingCtrl+Click.Dependencies can now be defined between COBOL reverse projects using standard Eclipse project dependencies. For this purpose, right click on the project and use
Properties > Project References. Once dependencies are defined, calls to COBOL programs from dependant projects can be followed.
Note: some modifications must be performed in the SubstitutionProperties.xml file of existing projects. Please see section Section 4.3.2.2.1, “Template Writers” below.
The CRUD services or operations creation wizard now honor usual naming conventions (operation + entity name: “
saveCurrency”, “udateCurrency”… or service + operation + entity name). Moreover, it is not necessary to input an operation name in the operations creation wizard: the generated operation will be named operation + entity name.
Multiple resource folders can now be added in the KDM configuration. The first one will then be standard generated resources; the following ones can be used through
dir defs. They will then be taken into account in the classpath and POM.The value of the
appendtag of the EBCDIC writer if now properly taken into account.Generated parent
POMs now properly reference modules.BAGS arithmetic operators on
BigDecimalvalues are now properly generated as operations.
lineSeparatorhas been added to template writers. It has the same behavior as on the flat file writer: thelineSeparatorOutworkflow option will be used, excepted if it is set toNO_VALUE.The following modifications are mandatory in existing
SubstitutionProperties.xmlfiles for properties of template writers orwrite_template_line_operation:The
CHARSETproperty must be renamed toINPUT_CHARSET.The
FORMATproperty must be added. For more details, see below.
A
FORMATproperty was added inSubstitutionProperties.xml. It controls the format specification of output fields and must take one of the following (case sensitive) values:String: the JavaString.formatspecification is used.Template: this format is a superset of JavaMessageFormat, extended to specify a length and alignment for each pattern:Valid pattern formats are the following:
MessageFormatPattern,MessageFormatPattern[Length],MessageFormatPattern[Length Alignment].
Lengthis an integer specifying output size; characters will be truncated if the formatted value is too long, or padded with spaces if too short.Alignment is either “
r” or “l”, respectively for left and right alignment. If not specified, right alignment is implied.
The PD (Packed Decimal) sort mode is now supported. Note that the file lines must be delimited through
recordLength: CR and LF delimiters cannot be used since they may appear in a packed encoded value.VB (Variable Block) files sort is now supported. For this purpose, the
isVariableBlocktag of theSORT_STEPstereotype must be set totrue.
The
ebcdicDefaultValueworkflow option can now be used to control which byte if written byEbcdicEncoderwhen a value isnull. The possible values for this option areLOW_VALUE(its default),ZEROorSPACE.
It is now possible to control at runtime which copybook will be used by an EBCDIC writer. For this purpose:
A list of comma-separated copybooks must be defined in substitutions properties. Note that copybooks with different charsets are not supported.
A String parameter must be added in first position of the operation
write_ebcdic_operation. It will contain the simple name (no extension) of the copybook to use when writing.Multiple JDBC datasources in the same job can now be used. For this purpose :
A
Datasourcestereotype must be associated to aCallOperationAction(either a step reader or writer) or anInterface(service). Thedatasourcetag must contain the name of the datasource.The datasource properties are specified in the workflow, under a group property of the same name. The following properties are required:
driver,connectionUrl,usernameandpassword.
Files packaged in the service jar (copybooks, data files, templates…) can now be properly accessed.
An
encodingtag has been added to the following stereotypes (if this tag is not set, the workflow value is used):FlatFileReaderFlatFileWriterTextFileWriterTemplateLineWriterread_flat_file_operationwrite_flat_file_operationwrite_text_file_operationwrite_template_line_operation
<<process>>activities can now be owned by entities. This is especially useful to model synthetic attributes through getters and setters.Order of generated artifacts for entities now follow Java standards: attribute definitions, constructors, then alternate getter and setter for each attributes.
Unneeded fully qualified names in context casts have been removed.
Duplicated constants in
EbcdicDecodedandEbcdicEncoderhave been factored.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Rare low-level errors could halt the parsing of COBOL programs (Eclipse message “An internal error occurred during: “Updating project”). Now, should those happen, they will be displayed in the “Problems” view, under the “Unexpected Parsing Error” type.
Parsing of the
NOT INVALID KEYconstruct is more robust.SOURCE-COMPUTER/OBJECT-COMPUTERentries in theCONFIGURATIONsection andSYMBOLIC CHARACTERSin theSPECIAL-NAMESsection do not halt parsing anymore.Parentheses in the replacement source of
COPY REPLACINGare supported.“
SYSLIB” and “FOR RESPONSE” are now accepted in “CALL” verbs.“#” is now accepted in PIC formats.
More PIC variants are supported (order of specifications is more flexible).
More
STRING/UNSTRINGvariants supported (DELIMITEDis now optional).Parsing of intrinsic
FUNCTIONexpression has been improved.The
DO PERFORMvariant is now supported.
File search results in COBOL programs are not offset anymore by copybooks inclusion.
An “ALL” category was added in statistics export and combo box.
Order of categories is preserved in statistics export.
The Category preference is now synchronized with the editor.
The Statistics view does not cause slowdowns anymore.
Included copybooks are now properly taken into account in lines count.
Linking (
Ctrl+Click) toFILE DESCRIPTIONfrom file manipulation verbs is now available.Linking to programs will now use in priority the
PROGRAM-IDto identify the target program, then fallback to the file name.Common
COPYBOOKs are now included in programs (SQL ORACA,SQLSAandSQLCA).Any textual file can now be annotated. For this purpose, use
Right click > Open With > Annotation Text Editor. Statistics for those annotations can be generated from the Statistics View.
Note: the following properties concerning template writers have been moved from substitution properties to stereotype tags: INPUT_CHARSET, FORMAT, HEADER and FOOTER. UML models will need to be adjusted accordingly.
The Business Object creation wizard is now robust to the existence of an activity diagram homonym with the entities folder.
Sort Step
XML special characters in sort cards configurations (
sort,sum,omit,include,inrecandoutrec) will not halt Spring configuration loading anymore.An exception is now thrown when reading an RDW size of zero.
Sort with multiple inputs will not fail anymore when output file does not exist.
Comparison between a field and a differently-sized string (as specified in INCLUDE tag) now behaves similarly to DFSORT.
Abend of a job will not cause an error when closing
EbcdicFileReaderanymore.
The
<<Datasource>>stereotype is not considered as invalid onInterfaceanymore by the batch model validator.The “
file” property of the<<read_ebcdic_operation>>is mandatory, and is now validated as such.Steps not needing an Activity diagram (SORT, FTP…) do not generate initial and final validation errors anymore.
To write different template lines in a file while ensuring the lines order, a single operation stereotyped
<<write_template_line_operation>>must be used. This operation must bear two parameters:The first one (of type String) is the line identifier.
The second one (of type List) is the parameters list.
Note: in this case, do not use the “
recordWriter” tagged value.Multiple lines can be written at the same time in a
<<write_template_line_operation>>while referencing only one line identifier. For this purpose, create a lines group with an empty identifier for all lines except for the first one, which contains the group identifier. As an example, the following lines define a group identified by “table header”, writing two lines when used:table header:COLUMN 1 COLUMN 2 COLUMN 3 :-------- -------- --------
In configuration cards (sort, sum, omit, include), the field format must be either explicitly be specified, or a default format must be provided using “
FORMAT=”. Failure to do so will now throw an exception.Formatting of numeric fields using
EDIT,SIGNS,LENGTHand predefined types (“Mx”) is now supported.
The EBCDIC reader now accepts leading spaces in zoned decimal values.
The EBCDIC reader now owns a “
hasRDW” tagged value to specify that it contains RDWs. Similarly, the EBCDIC writer owns a “writeRDW” tagged value.Attributes of sub-entities can now be accessed when using group readers. For this purpose, list the path to the final attribute, separated by ‘
.’. Note that this will not work with fields having several occurrences.An encoding tag was added to the following stereotypes:
FlatFileReaderFlatFileWriterTextFileWriterTemplateLineWriterread_flat_file_operationwrite_flat_file_operationwrite_text_file_operationwrite_template_line_operation
If the tag is not set, the workflow value is used.
A
<<return_generated_key>>stereotype can now be applied to<<sql_update_operation>>methods to specify that an automatically generated identifier must be returned. For this purpose, its “key” tagged value must specify the generated key name.
An
<<EMAIL_STEP>>stereotype can now be placed on an Activity. It can be configured using the following tagged values:host(mandatory): the SMTP server address.port(25 by default): the SMTP server port.useSTARTTLS(default:false): whether STARTTLS must be used.username: user authentication name.password: user authentication password.from(mandatory): sender address.to: comma-separated list of recipients.cc: comma-separated list of copy recipients.bcc: comma-separated list of hidden copy recipients.subject(mandatory): the mail subject.encoding(default:Workflow.encoding): the encoding to use for the mail.inputEncoding(default:Workflow.encoding): the encoding of the file providing the mail body.
At least one recipient must be provided (
to,cc, orbcc). The message body is read in a file specified in substitution properties ("job.step.body").
The following methods are now available to handle counters in the
StepContextManagerandJobContextManager (StepandJobscopes):setCounter(String, long) : voidgetCounter(String) : longincrementCounter(String) : voiddecrementCounter(String) : void
The last three use a default value of “0” if the counter does not already exist.
The counter is a standard context variable and as such can be accessed using existing related methods (
putInContext,getFromContext…).
A
<<contextVariable>>stereotype is now available. Its “scope” tagged value (default:step) specifies whether it is a step or job scoped variable.
Generation Data Groups (GDG) can now be referenced in the substitution property by using the “
gdg-read:” or “gdg-write:” prefix instead of “file:” to specify the file. The possible syntaxes are either:gdg-x:path/to/file(<n>)gdg-x:path/to/file(<n>).<extension>gdg-x:path/to/file(<n>|empty)gdg-x:path/to/file(<n>|empty).<extension>
Syntax detail:
gdg-x can either be “
gdg-read” or “gdg-write”, to specify either access or writing to files in groups.While reading,
<n>represents the referenced version of the file (+1: the version written in current job, 0: the previous version, etc.). While writing,<n>represents the maximum number of files (as specified byLIMITin legacy code). An asterisk “*” can also be used to denote “all files of the group” during a read access.The “
empty” option can be added to specify that all files must be deleted when the limit is reached (EMPTYin legacy code). The default behavior is to remove the oldest file.The file extension is not mandatory. It can be specified after parentheses.
As an example, an output specification of
gdg-write:data/output/REPORT.(3).txtwill first create a file namedREPORT.G0000V00.txt, then a file namedREPORT.G0001V00.txt, etc. At the fourth writing, REPORT.G0003V00.txtwill be created andREPORT.G0000V00.txtwill be deleted.
A “
strict” tagged value (default:true) was added to jobs. If true, the job will fail when a resource (file to delete, to merge…) is missing. If false, a warning is logged and execution continues.A “
transactionTimeout” workflow property (default: 10) is now available to specify the value of the Atomikos transaction timeout indata-source-context.xml.
The code quality has been improved in
Formatter,Sum, FilterBuilderandCharFilterclasses.log4j.propertiesis now generated insrc/main/configwhenappAssembleis activated.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3) ;
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new Licence Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configuration mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
The renaming option for inputs proposed by the COBOL reverse projects creation wizard now searches for JCL scripts. When such a file is identified, it is renamed with the «
.jcl» extension (and no longer «.cpy»).Duration of initial built of COBOL reverse projects has been reduced.
ON [NOT] OVERFLOWconstruct is now recognized.TIMEOUTis now valid as an identifier.Handling of the
COPY … REPLACING ==XXX== …syntax has been generalized.
When a COBOL paragraph and section have the same name and a
PERFORMor aGO TOtargets this name, Ctrl + Click from these verbs will reach the paragraph instead of the first element found.The
INDEXED BYconstruct does not cause a warning any longer, and can now be reached by Ctrl + Click.
Considering the following COBOL code:
IF <condition>NEXT SENTENCEELSE<Statements>
Its transmodeling now generates a test with a reversal of the condition. There is therefore no more opaque generated for the NEXT SENTENCE.
The
STRING … INTOverb is now supported forDELIMITED BY SIZEandDELIMITED BY <literal>operators, with reading and writing into elementary fields.The
INITIALIZEverb is supported for the initialization of the elementary fields.It is now possible to modernize (using the wizard Transient Object Modernization) and transmodel level 01 fields directly owning levels 88.
A caching mechanism is now provided. It can significantly improve the initialization time of the transmodeling wizard starting from its second launch. To activate it, tick the following checkbox in the preferences: «
Blu Age⇨Blu Age Reverse⇨Model Transformation⇨Generic Model caching».A mechanism allowing to choose the type of activity diagrams generated by the COBOL transmodeling has been set up.
By default, the previous behaviour has been preserved (generation of the
<<Process>>activity and the associated operation).When checking «
Blu Age⇨Blu Age Reverse⇨Transmodeling⇨Choose Activity Type on generate transmodeling wizard», you can select the type of activity to generate by default (<<Process>>or<<ProcessOperation>>) :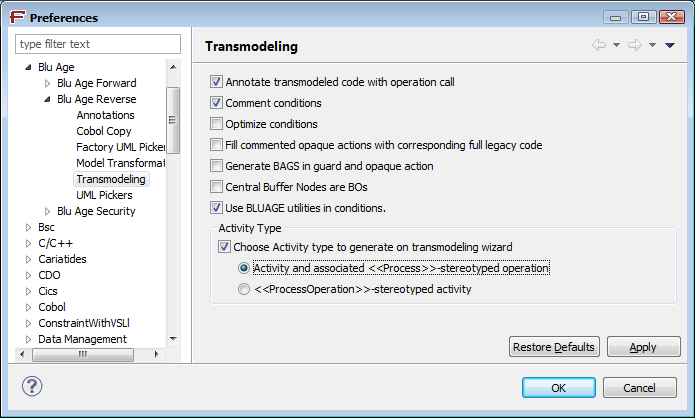
Ticking this option triggers the display of an additional column «
Generate Process Operation» in the transmodeling wizard :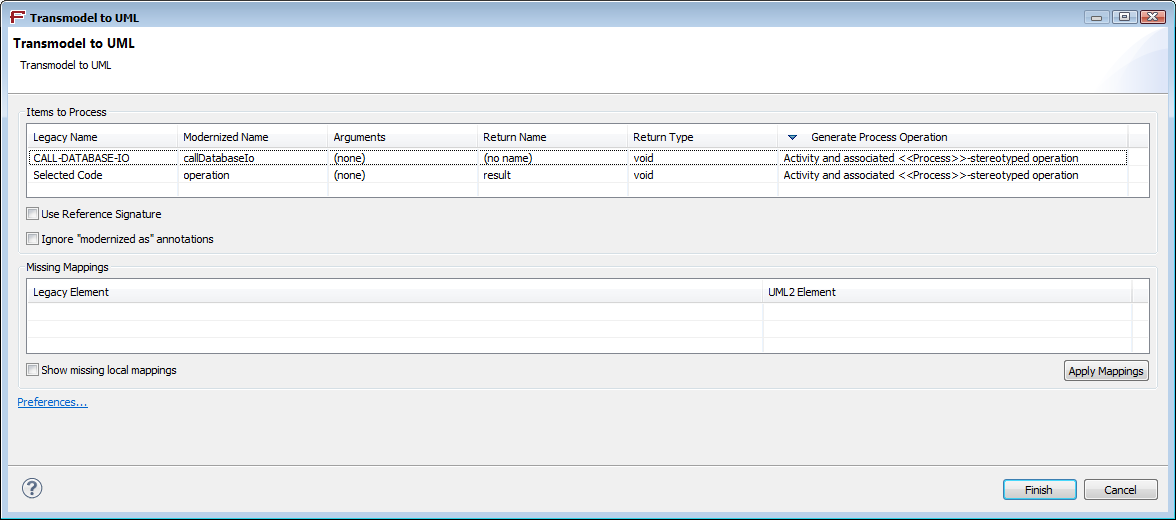
This column is editable, therefore the type of activity to generate can be chosen for each line when necessary :
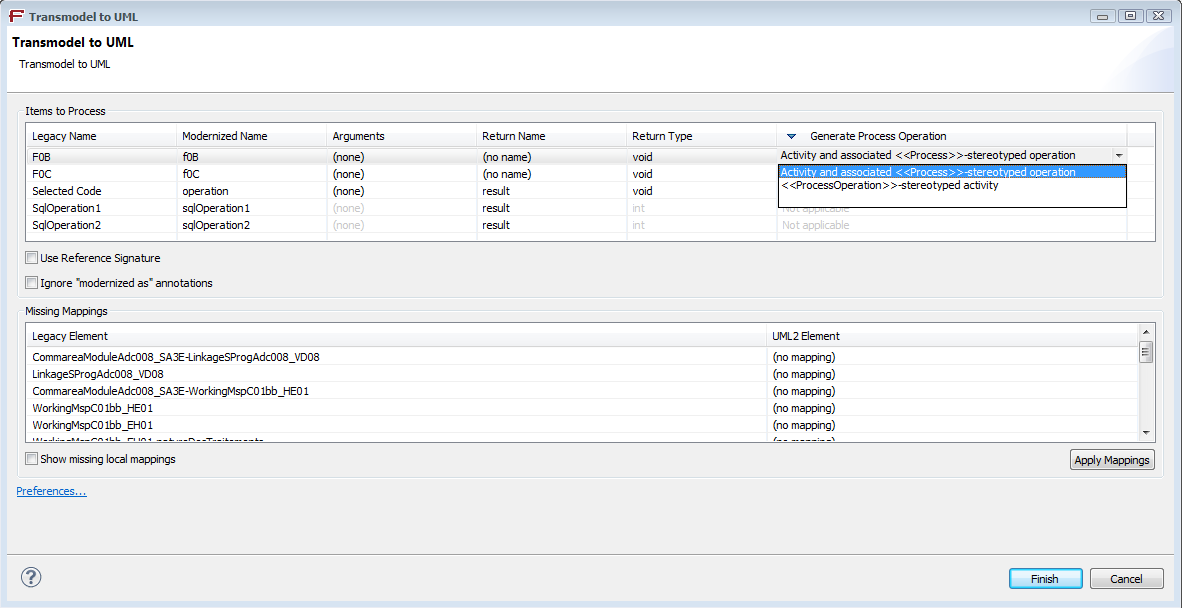
A contextual menu on the column title allows to change the status of all entries of this column at once:
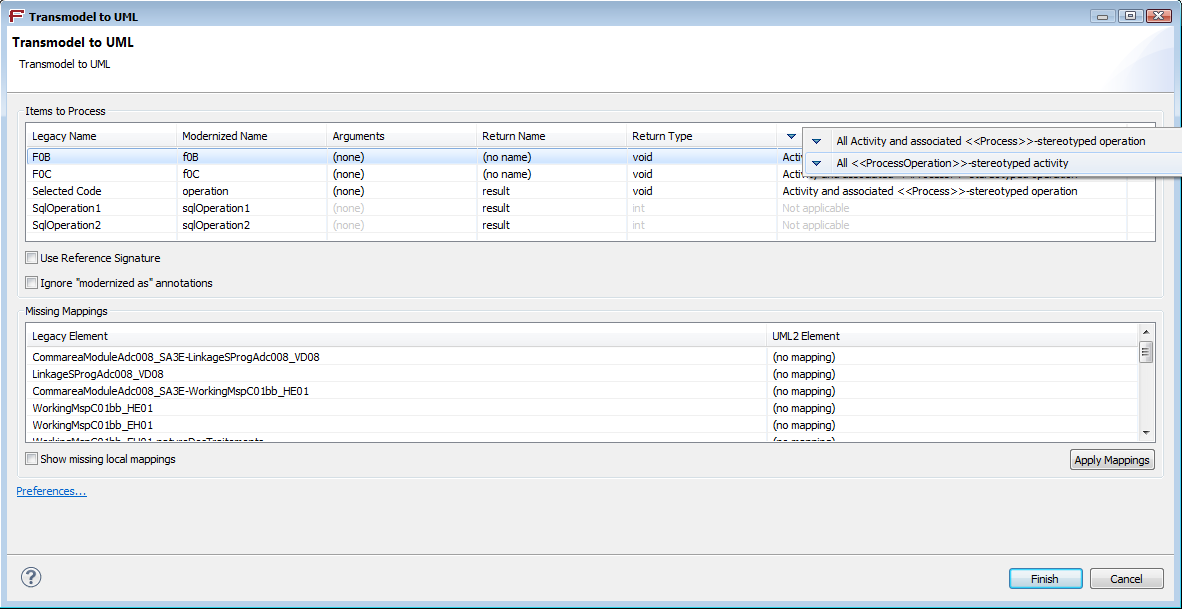
The
hasrdwproperty of the<<ebcdic_read_operation>>is now generated at the right place.
The value of
clientModeandfileTypeproperties of theFTP_PUT_STEPstereotype is now correctly handled.
The behaviour regarding GDG numbering is as follows :
If a GDG file does not exist and n<=0, a warning is logged. There is no immediate error as it would stop the use of
<<STEP_EMPTY_FILE_CHECK>>. The reader will send itself an exception when opening the referenced file.If there is no file, the version 0 of the file is considered as
G9999V00, so that the version +1 (so the first created file) will beG0000V00.
Accesses to boolean properties BAGS are now using the
isXXXmethod when present.The
PreparedStatementare now correctly released in case of an exception.
StringUtils#substringBefore,StringUtils#substringAfterandStringUtils#stripEndutilities have been added to the UML profile.The
BigDecimalUtils#subtractutility has been added to the UML profile. It is still possible to generate the «substract» method when setting the option of «donotGenerateDeprecatedOperations» workflow tofalse.
A new "
useDatabase" workflow option has been created. It istrueby default (unchanged behaviour). In the case of a job that does not require an interaction with the database, the option can be set to false in order to avoid to specify connection information in the launch config.
It is now possible to generate a job only consisting of a
<<FTP_PUT_STEP>>step.It is now possible to generate a step only consisting of a sorting step.
It is now possible to generate a job consisting of two
<<FTP_PUT_STEP>>steps.
A
gdg-optionsproperty allows to specify the maximum number of generation for a GDG file. Each file is identified by its simple name followed by the string «(*)» and its extension (example: "file(*).txt"), then by two parameters : the limit (maximum number of generations in the dataset) and the mode (empty/noempty). The limit by default is 0 (in which case, all files are kept); the mode by default isnoempty(see below).For example:
limit=10,mode=noemptyIn this case, if the dataset has already 10 versions and we have to create a new one, we delete the oldest one.limit=10,mode=emptyIn this case, if the dataset has already 10 versions and we have to create a new one, we delete all previous versions.
When generating BAGS expressions in an activity diagram handled by a BO or an entity, « this » and its attributes (even the inherited ones) are now referenced.
The compare feature is now accessible via an Eclipse launch configuration.
This launch mode is recommended over the previous comparison wizard that will be gradually depreciated.
EBCDIC, Database and FlatFile comparisons are available.
For all cases (Ebcdic, FlatFile, BDD), the comparison project is based on a fixed structure that has to be filled out by the user before any comparison. This structure is as follows:
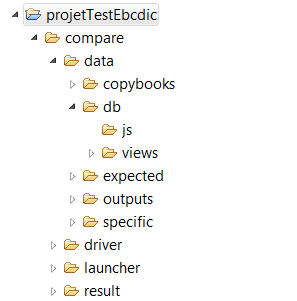
Copybooks: must contain all Copybooks, mandatory for the Ebcdic comparison.
Expected: contains all Ebcdic or FlatFile files to be compared.
Output: contains all current Ebcdic or FlatFile files to be compared.
Specific: must contain all substitution files.
Driver: must contain the drivers required for database comparison.
Db/views: must contain BDD views.
The
Outputdirectory is optional, it is here by convenience. The output directory can be anywhere, its location has to be specified in the launch configuration (see screenshots below).The launch Configuration consists of 5 tabs: Common, Database Comparison, Ebcdic Comparison, FlatFile Comparison and Save.
The
Commontab contains all common properties of the comparisons. The name and the type of the comparison project must be entered : Ebcdic, Database, FlatFile :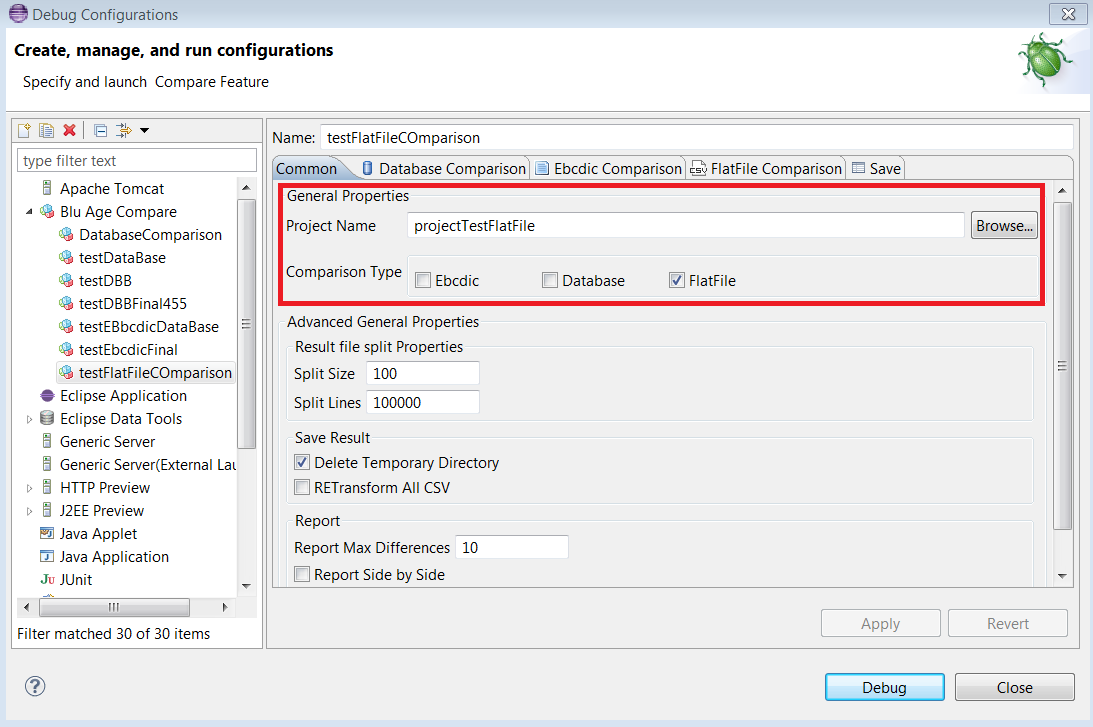
The
Database Comparisontab allows to enter the required properties when comparing BDD (see the following example).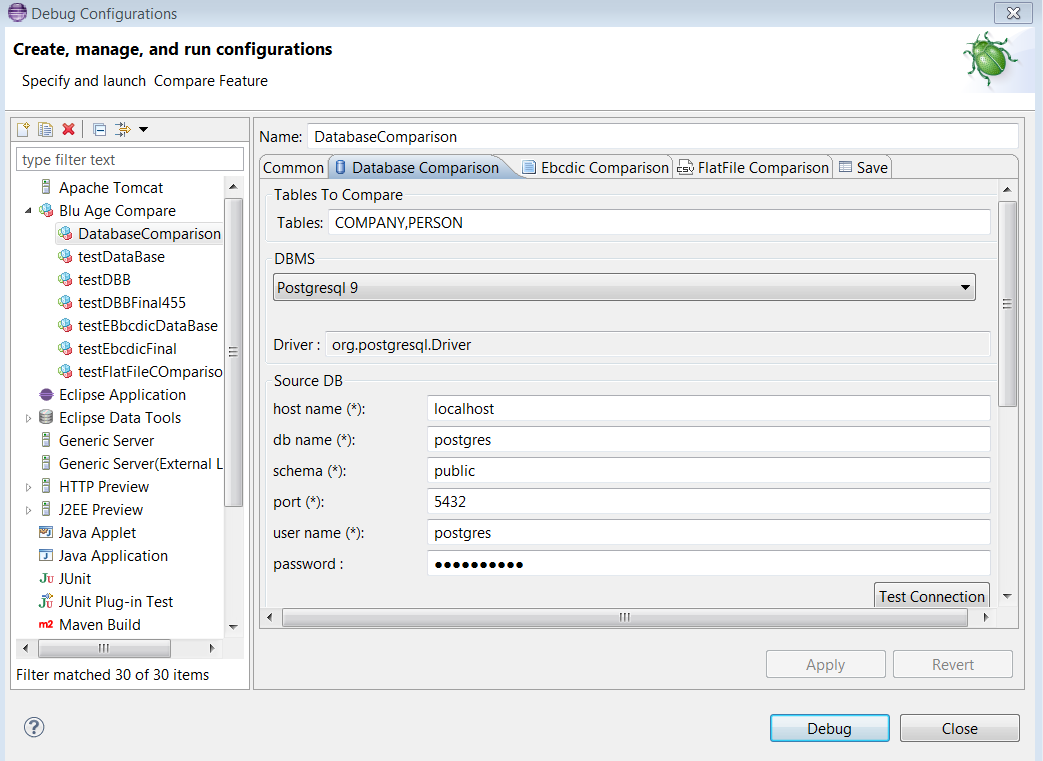
The
EBCDIC Comparisontab allows entering required properties for an Ebcdic comparison. The user must fill in the name of Ebcdic files directory that he wants to compare (see the following example).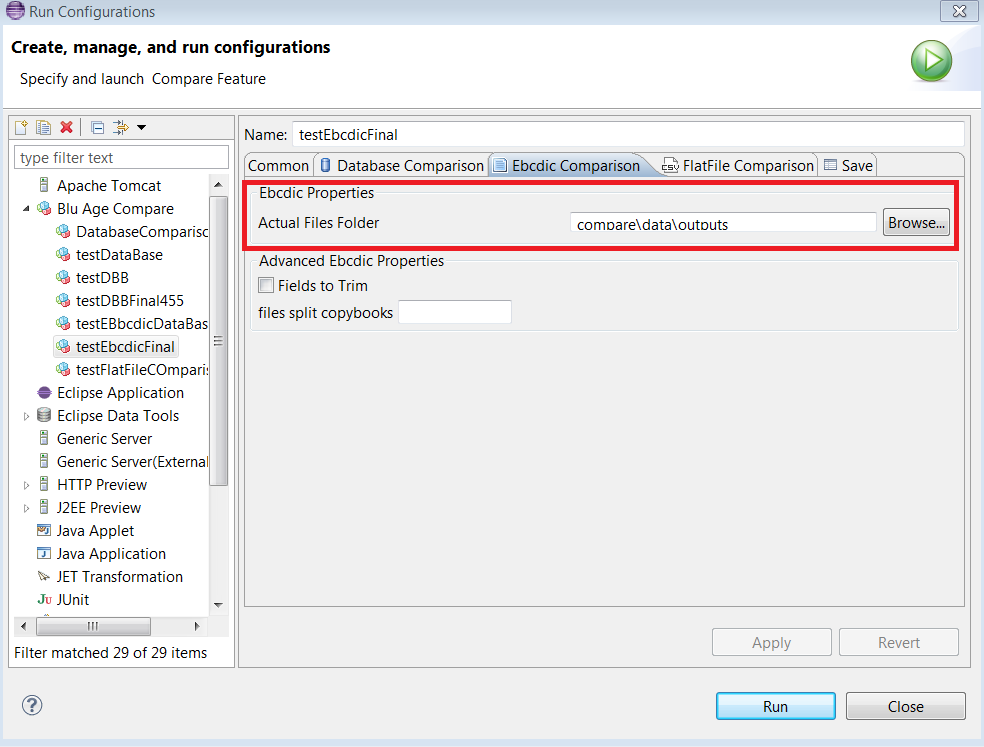
The
FlatFile Comparisontab allows to enter the required properties for a FlatFile comparison. The user must fill in the FlatFile files directory that he wants to compare (see the following example).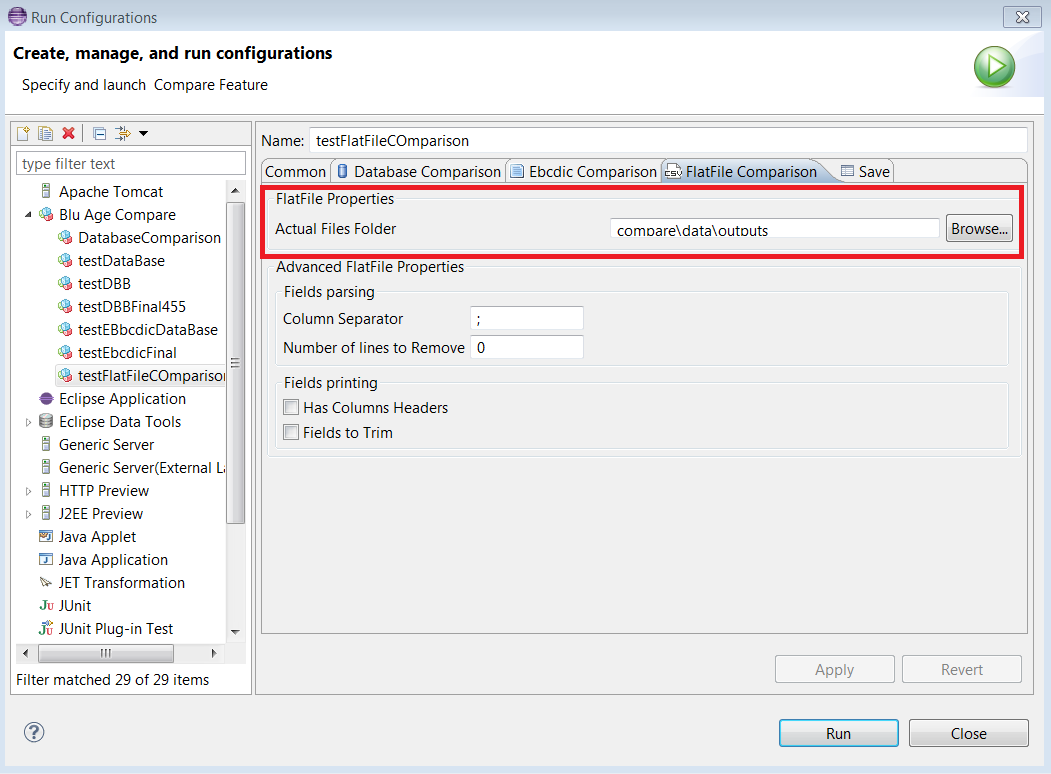
The
Savetab saves the settings in the project (see the following example).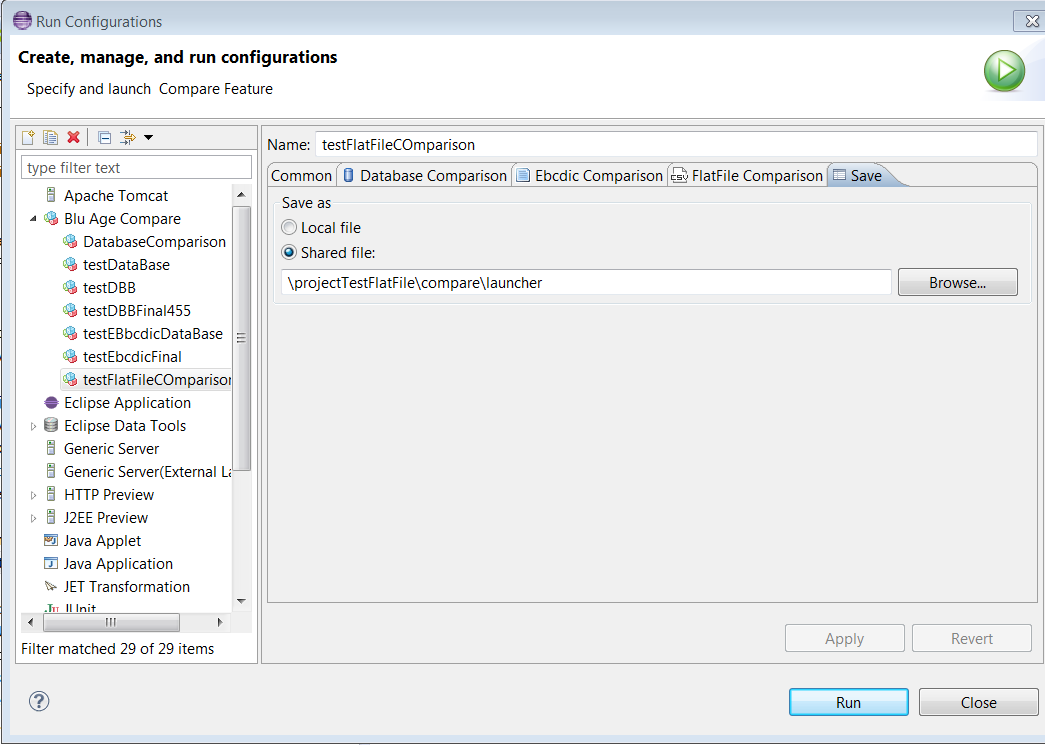
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
The DWP variant of the SpringBatch relies on:
JPA2 for the entity layer
EJB3 for the service layer, with a dual implementation for Spring compatibility
SpringBatch for the job/step layer
Bytecode enhancements with Lombok framework
Dozer for automatic conversion of data objects between layers
Bespoke framework classes supplied by the customer. The path to this framework must be setup in the “
bespokeFwkPackage” workflow option.
Please note that the Lombok framework is not provided in this release. To install it:
Download the Lombok framework (http://projectlombok.org/download.html )
Copy the downloaded jar in the %BLUAGE_INSTALL_PATH%/BLUAGE/eclipse folder
Add this line at the end of the bluage.ini file :
-javaagent:lombok.jar
The specifics of this technical stack requires some custom modelling practices, which will be described below.
These layers are shared with the online product, so the rules are the same. Please refer to the Release Note for product Cobol2JSF2EJB3JPA2 DWP for details (chapters 2, 3 and 4).
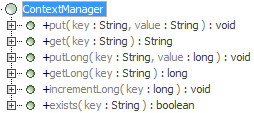
The
CacsContextclass and itsContextManagerare automatically added in the entity/dm layer, provided thegenerateContextClassesworkflow option is set. The context manager is automatically referenced in the Jobs, and can be invoked in the job configuration.The context is also available through a new interface in the dwp profile:
This product uses the usual batch modelling, with some specificities. One of the main differences is that no substitution properties are used. Instead, step attributes and/or action pins must contain the file names.
#{…}constructions may be used to reference other variables in such names. For example:#{cacs.get(‘key’)}to call the context manager.#{var}to use another declared String variable.
As usual
<<PK_JOB>>will contain the Jobs and<<PK_STEP>>will contain the steps. But the target architecture requirement impose that the corresponding classes are in the same place. Thus, the<<PK_STEP>>and<<PK_JOB>>packages must be the same one.The generated elements for each Job are the Job Launcher class and the Job configuration XML file. All these XML files are generated in the
META-INF/batch-jobsfolder.The generated elements for each step are the some classes for readers, writers and processors as listed below, as well as tasklets for empty-file-checks.
A job diagram consists in a set of steps.
The allowed steps are of five types listed below.
The steps may be sequential or conditional. Decision and Merge nodes may be used as in normal batch modelling, with guard conditions.
Job may have inner attributes. Two attribute types are allowed:
StringandObject. If the type isString, the attribute default value will be used as the value, if the type isObject, the attribute default value will contain the fully qualified name of the class to reference. This can be used to obtain this kind of setup (excerpt of the sample application):
![]()
The most usual step type is the read/process/write step, which bears the
<<STEP>>stereotype. It contains a reader, a processor and a writer as in normal modelling.Empty-file-check steps are available through the
<<STEP_EMPTY_FILE_CHECK>>stereotype. The guard conditions to use are“EMPTY”and“NOT_EMPTY”.An input pin must be added in the job diagram: its name must be the file name
Merge steps are available through the
<<FileMergeTasklet>>stereotype found in dwp profile. If no more setup is added, it will use the default implementationSimpleFileMergerfound in the framework. The merger tagged value can be used to link a different class (fully qualified name expected) that may be supplied as a specific class.Two attributes must be added in the step activity:
inFileListandoutFile.InFileListdefault value must contain the input file names, separated by commasoutFiledefault value must contain the output file nameExample:
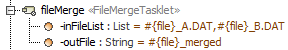
Sort steps are available through the
<<FileSortTasklet>>stereotype found in dwp profile. If no more setup is added, it will use the default implementationSimpleFileSorterfound in the framework. The sorter tagged value can be used to link a different class (fully qualified name expected) that may be supplied as a specific class.Two attributes must be added in the step activity:
inFileandoutFile.InFiledefault value must contain the input file nameoutFiledefault value must contain the output file nameExample:

Fully specific tasklets can be used. The step must bear the
<<CUSTOM_STEP>>stereotype and the implementation tag must be filled. The class must be supplied as a specific class.Step attributes may be added.
String,ObjectandListtypes are allowed. The default value will contain the String value forString, the object reference forObject, and the String values separated by commas forList.
The allowed readers are
<<FlatFileReader>>,<<JDBCReader>>and<<JPAReader>>.<<GroupReader>>can also be used in addition.The allowed writers are
<<FlatFileWriter>>,<<JDBCWriter>>,<<JPAWriter>>,<<TemplateLineWriter>>and the special<<SQLScriptWriter>>.The readers and writers setup is similar to normal batch modelling, except that:
The files must be supplied as input pin (for flat file readers and SQL script writers, as well as the template supplier file for a template line writer) or output pins (output files for flat file writers and template line writers)
FlatFileReaderuses the“fields”tag to store the column names. (In normal batch modelling, the<<COLUMN>>stereotype is used on entity attributes. This stereotype is not used in this product)Example of
FlatFileReadermodelling:
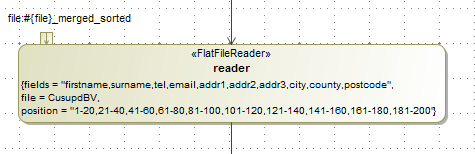
The processor can be a Call Behavior Action referencing a process operation in the service layer, as in normal Batch modelling.
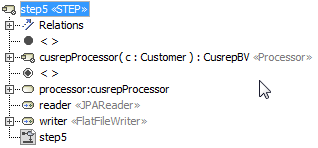
The processor can also be a Call Behavior Action referencing an inner process diagram. This kind of modelling is similar to the Rich UI event modelling.
This specificity can also be used for preprocessors and postprocessors. In these cases, as usual, the Call Behavior Action must bear the
<<PreProcessor>>or<<PostProcessor>>stereotype, respectively.For these inner process diagrams, the new <<Processor>> stereotype can be used. It is only an eye candy, so that the inner diagram is easily seen in the containment tree. It is not mandatory.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Functionalities are provided so as to ease analysis of the algorithmic of JCP/SCL scripts. For this purpose, the script can be displayed, navigated and annotated, and language constructs are modernized as UML representations in a way that will be detailed below.
To use those functionalities, scripts must have the .jcp or .scl extension and be copied in a COBOL Reverse or General Eclipse project. In the latter case, please accept adding the Xtext nature when asked for it while opening one of those files for the first time.
Files can then be opened in an annotation editor by double clicking on them or by right-clicking > Open With > SCL/JCP Annotation Editor. This editor provides the following features:
Syntax highlighting and folding.
References navigation: when Ctrl+clicking on a symbol, the editor jumps to its definition (a variable declaration or a procedure parameter, as an example). Note that due to the dynamic nature of the language, not all symbols have associated definitions.
Annotations definition and edition.
Language constructs can also be visualized as UML diagrams. For this purpose, the following prerequisites must be met:
A Blu Age UML model must be opened.
The following options have to be selected in preferences:
Blu Age>Blu Age Reverse>Transmodeling>Generate BAGS in guard and opaque actionBlu Age>Blu Age Reverse>Model Transformation>Generic Model caching
The generation functionality can then be accessed from this editor by selecting lines of code and right-clicking > Transmodel To UML2.
A wizard will be displayed; press “Finish” and the UML corresponding to the selection will be created in the currently opened UML model. The mapping between JCP/SCL language constructs and UML is provided below.
Generally speaking, UML constructs similar to those generated by Blu Age code transmodeling are used to represent JCP/SCL constructs:
Variable declarations are represented as central buffer nodes.
Basic arithmetic and boolean expressions are copied “as is”, especially with respect to symbols and inner function calls. When possible, operators are transformed to “modern equivalents: “
EQ” becomes “==” as an example.Assignments, functions and procedure calls are represented by opaque nodes. Should they contain inner expressions, the previous rule applies.
The “
IF” construct is represented as a pair of “diamonds” (decision nodes) and a pair of control flow edges. The edge corresponding to “THEN” bears a guard, whose boolean condition is filled using the rules above.The “
UNLESS” construct is generated using the “IF” rule, but the condition is negated.The “
WHENEVER” construct is generated using the “IF” rule. It bears an UML note warning about its specificity (evaluated each time the associated variable value changes).The control structures (“cycles”) are represented using an expansion region. The associated looping condition is represented as an associated expansion node. When required, UML nodes are inserted to update this condition or the loop variable.
The following have been added or improved since the last “preview” release:
A linker for SCL/JCP scripts has been added.
Loop variable update node is now properly generated.
“Could not find a compatible type” notes are not generated anymore.
Parameters are not added to signatures anymore.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3) ;
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new Licence Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configuration mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
A spurious duplicated files warning popup will not be displayed anymore when renaming COBOL inputs during COBOL reverse project creation.
When the “
Rename According To File Content” box of the COBOL reverse project creation wizard is unchecked, no more renaming take place. The previous behavior was that all files were renamed to a “.cblmf” extension.
Filtering of displayed mappings by UML field, class and package now works properly.
A rare case of transmodeling error (“
More than one rule registered for PerformStatement”) was fixed.Generated UML does not contain unneeded “TODO” anymore when transmodeling COBOL indexed access.
Unnamed associations between classes are now robustly handled by transmodeling when targeting BAGS.
Calls to
BigDecimalUtils#subtractare not generated as “substract” anymore.
COBOL parsing speed has been increased.
Parsing of string literals “continuated” on multiple lines has been improved.
Those UNISYS-specific constructs are now properly parsed and linked:
Database and dataset specification in a data section.
“VALUE OF” clause on files definition.
LOCK and CREATE statements.
Variants of USE, CALL, FIND, STORE statements.
“VA” alias for VALUE.
DUPLICATED, STATUS and TITLE keywords used as IDs.
A rare case of missing EXEC SQL PREPARE line after copybooks insertion was fixed.
Usual, unneeded star characters (
*) at the beginning or end of COBOL comments are now removed during transmodeling when generating UML notes. Should the resulting comment be empty, or only composed of spaces, no note will be generated.
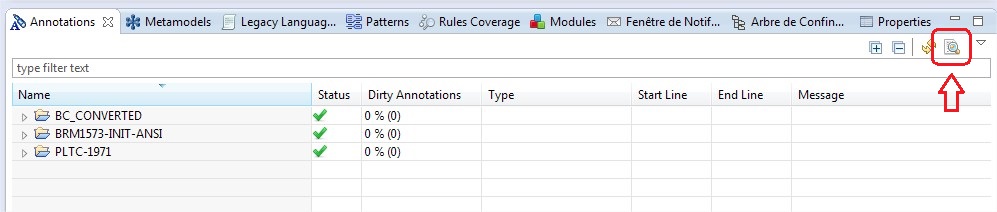
A report can now be generated to ensure that all “Modernized As” annotations properly point to existing model elements.
The associated wizard is launched from the “Annotations” view:
Select resources to check, and then press Next:
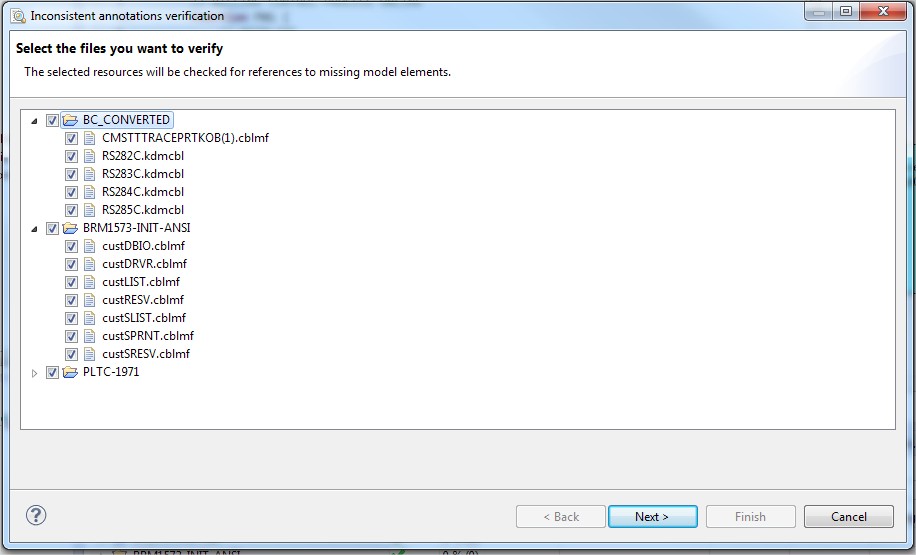
If annotations containing obsolete references are present, they are listed on the following page:

To generate the associated report, check the “Generate HTML Report” box on the lower left and choose the save location.
Writers using a non-parameterized SQL request are now properly generated.
Files merge using
FILE_OPERATION_STEPis now robust in situations where the target file is part of input files. The behavior is the following:When using a “
MERGE” operation: the content of each source file is added at the end of a temporary file. The content of that temporary file is then appended to the target file.When using a “
MERGE_COPY” operation: the content of each source file is added at the end of a temporary file. The content of that temporary file then replaces the content of the target file.
FTPGetStepandFTPPutStepclasses now properly take into account logger configuration when using a non-default one.
When a property is present in an entity / BO, and a getter or setter operation of the same name (either stereotyped
<<formula>>or<<process>>) is modeled, the resulting java operation is now only generated once. In this situation, the modeled operation takes precedence, and the default accessor is not generated.<<sql_update_operation>>methods executing non-parameterized requests are now properly generated.“
+” prefixed literals are now accepted in BAGS expressions.The implementation of
DateUtilshas been improved.Spurious “
Reference from … cannot be exported” log messages will not be displayed during code generation anymore.
Dependency to the JDBC driver is now added when creating a SpringBatch project. For this purpose, a new wizard page has been added so as to specify database parameters. The “active” box must be checked to take those parameters into account. Should this box be checked and parameters also added to the existing page (see below), this new page takes precedence.
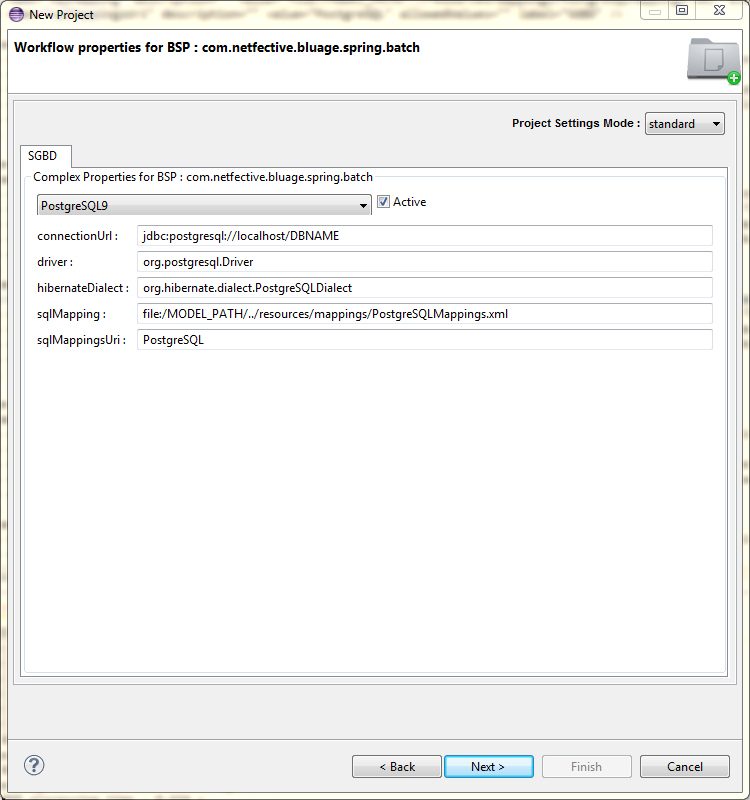
For coherency reasons with the previous point, the following wizard page has also been modified. Some of its properties are now only displayed in “Advanced” mode since they duplicate properties of the new page. Those are:
connectionUrl,driver,SqlMappingURI.
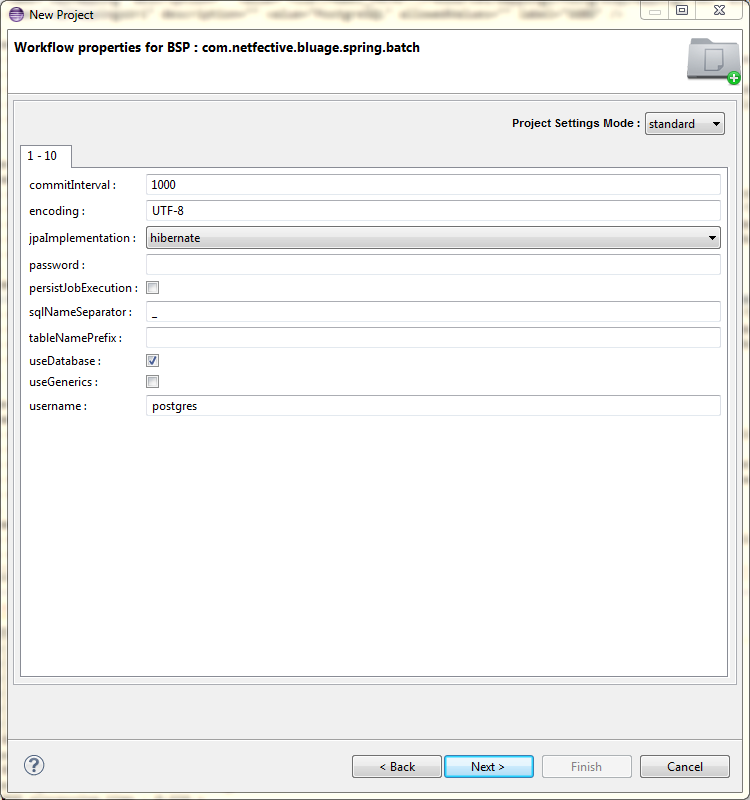
The latest version of the Compare Feature Launch Configuration is provided. All properties required by the different comparison modes (EBCDIC, DB, FlatFile) are available.
Headless execution of the compare feature requires the specification of the path to the Launch Configuration (as shown below).

Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
The COBOL “
IS NUMERIC” condition is now properly transmodeled as a call to theStringUtils.isNumericBlu Age utility.
The
getDifferenceInDays()method ofDataUtilsnow returns the proper value when provided dates range spans daylight saving time.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” products family, built on Kepler (Eclipse 4.3) ;
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new licence management has been introduced, requiring the use of a new licence Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configuration mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from 3.X workflow to the launch configuration is described in a dedicated guide.
The following constructs of the COBOL Unisys variant are now parsed:
SECTION and PARAGRAPH IDs can be an INT
Declarative Section => USE AS GLOBAL PROCEDURE : AS is optional
USING clause added to Datasets (Record Database)
For segment definition:
"FROM DICTIONARY SAME RECORD AREA" ([KEY] IS [VALUE])
WITH keyword added
REAL keyword added
TYPE IS keyword added
@EEEE@ hexadecimal values are accepted
LOCAL-STORAGE section added
PROGRAM-LIBRARY section added
VA accepted as an alias for VALUE
OC accepted as an alias for OCCURS
REF accepted as an alias for REFERENCE
I-O accepted as an alias for INPUT-OUTPUT of SECTION
WITH USING and EXTERNAL keywords added to USE clause on section and paragraph
Accepted as ID and keywords:
MYSELF
AREAS and PROTECTED on FileDescription
LOCK statement :
Added keywords: STRUCTURE, FIRST, LAST, NEXT ...
Added AT clause
FIND statement:
Added keyword KEY OF
Added keyword de fin END-FIND
START and STOP statement on ID or STRING
CREATE statement:
Added ON EXCEPTION clause
Added CREATE XXX(INT) construct
Added keyword END-CREATE
CLOSE statement:
Added ON EXCEPTION clause
Added WITH keyword and CRUNCH option
Added keyword END-CLOSE
OPEN statement:
Added ON EXCEPTION clause
END-TRANSACTION statement:
Added ON EXCEPTION clause
SELECT statement:
Added keywords SORT, KEY
Added options: ASSIGN TO SORT DISK | PORT | PRINTER | READER | REMOTE | TAPE | VIRTUAL
STRING statement: Added keyword FOR
SORT statement:
Added clauses MEMORY SIZE IS and DISK SIZE IS
Added optional keywords on clauses GIVING SAVE | LOCK | RELEASE | NO REWIND | CRUNCH
DELETE statement:
Added optional keywords OF and NEXT
READ and WRITE statements:
Added option FORM
Added statements :
ENTER
FREE
RECREATE
CHANGE
ENABLE
DISABLE
WAIT
ATTACH
DETACH
SEEK
Added literal ATTRIBUTE
Added options to clause RECEIVED BY
Added field in clause COMMUNICATION AREA
Added TRUE and FALSE constants
Added VALUE literal in expressions
Handling of NULL literal, including when IS operator is implicit
Added USE ON clause on a section
Support for the copybook inclusion by fragments syntax: COPY [NAME] FROM [INT] THRU [INT] REPLACE ...
Beans can now bear synthetic operations, stereotyped with
<<formula>>or<<process>>.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
A set of improvements aiming at facilitating modernization of common cases of OCCURS definition and manipulation in COBOL are provided. Those evolutions target 1-dimension OCCURS of fixed size.
The Legacy Object Modernization wizard (aka TOM) will now modernize OCCURS fields as associations of the proper cardinality (when subfields are present), or typed Lists (for scalar types). Optionally those choices can be manually overridden to Blu Age array data types (
string[], etc.).Transmodeling generates appropriate BAGS access expressions for legacy expressions accessing the following mapped fields:
fields modernized as
Lists (by using BDM for instance),fields modernized as
Arrays of primitive types using TOM,fields modernized as Association with
0..*cardinality and a “@collection.type” stereotype set with a “list” value,previously mapped synthetic attributes describing access to collections (see “Mapping” section below),
While transmodeling COBOL OCCURS specificities (ambiguous subscripts, non-zero-based indexes) are taken into account.
Note that this improvement is not supported while transmodelling in “NO BAGS” mode. Hence checking “Blu Age>Blu Age Reverse>Transmodelling>Generate BAGS in guard and opaque action” in Preferences is mandatory to benefit from this feature.
As an addition to evolutions described above:
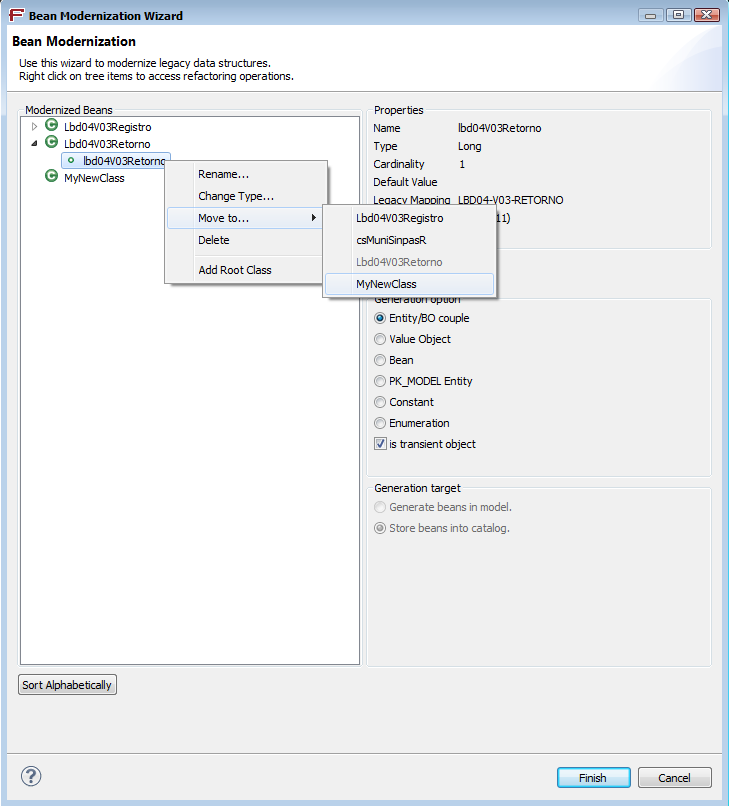
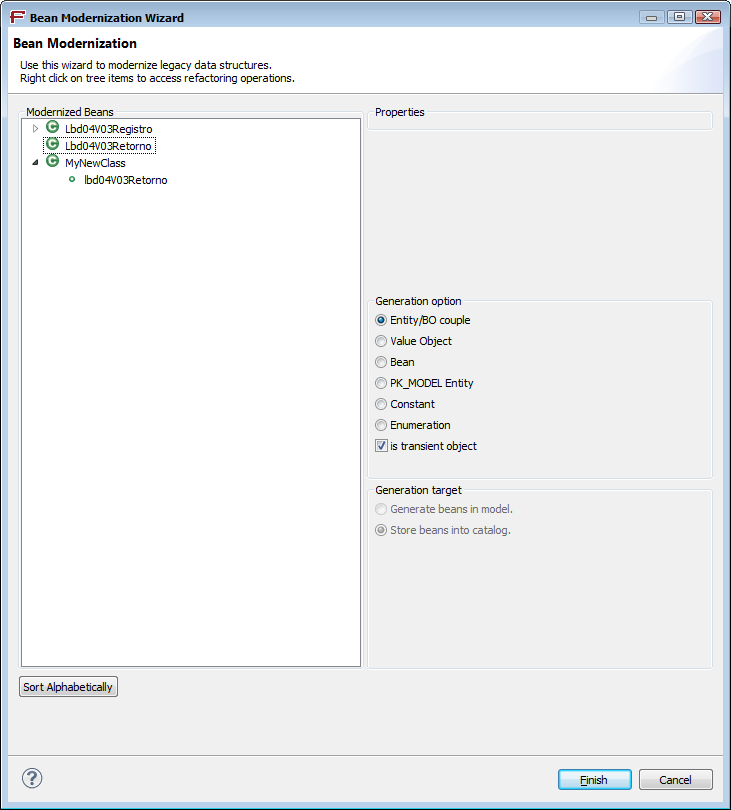
Classes can now be deleted in the Legacy Object Modernization tree. This is useful in the scenario where the fields of multiple legacy entities are moved in a single modernized one, hence leaving “empty” classes.
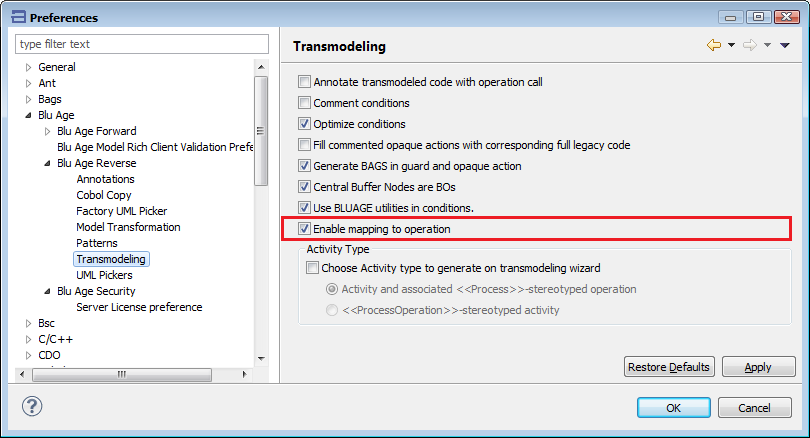
The transmodeling wizard now provides the user with the possibility to resolve “missing mappings” by pointing to synthetic getters and setters, either defined by hand or generated by the BDM tool. Once mapped, calls to those methods will automatically be generated by transmodeling.
By default this possibility is deactivated (only previous behavior, mapping to properties, is provided). To enable this feature, check the “Blu Age>Blu Age Reverse>Transmodelling>Enable mapping to operation” Preference:
Then, while transmodelling, getter and setter operations can be picked for unmapped elements as follows:
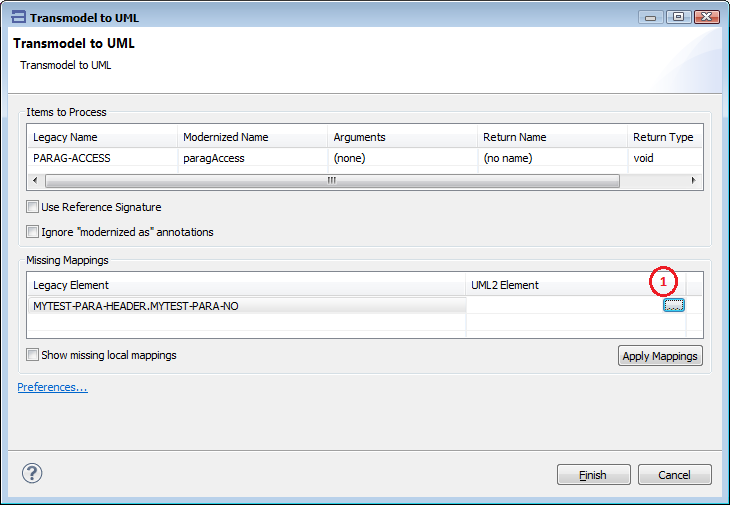
Make sure the “Blu Age>Blu Age Reverse>UML Pickers>Only show service operations” Preference is unchecked.
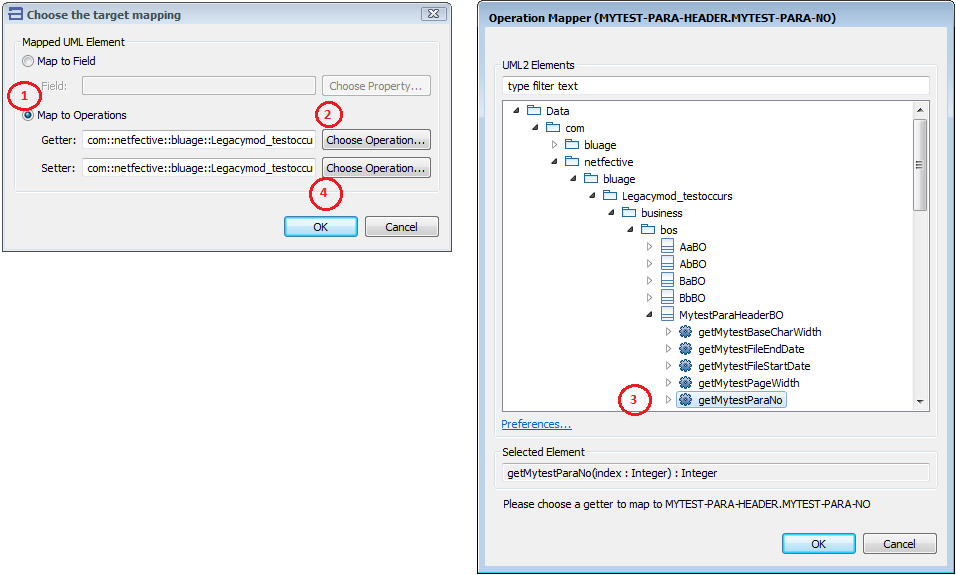
Validate all and finish transmodeling Wizard.
Transmodeling generates appropriate BAGS access expressions to synthetics getters and setters.
Here is an example of the resulting model and code:

Note that this improvement is only supported for indexed accesses for now.
As an addition to evolutions described above, it is now possible to pick <<bean>> elements (hence residing in PK_SERVICE).
FilenameBuildercan now be annotated with@Named. Its name tagged value property will then be used to generate the associated@Namedannotation in the generated service implementation.The
@OrderBy(“name”)tagged value is now taken into account on entities and properly generated.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
A new BSP was added in the product. It generates the various framework classes used by EBCDIC features. Its name is
com.netfective.bluage.dwp.ebcdic.The project where the classes will be generated is the Batch EPM one, due to dependencies between the framework classes and spring batch, which is only available in the EPM. They can then be dispatched in another location (e.g. in the foundation module) as usual.
The package where the classes will be generated is determined thanks to the
ebcdicPackageworkflow variable.
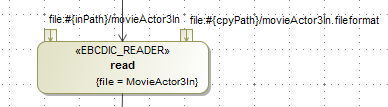
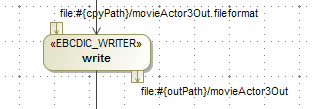
<<EBCDIC_READER>>was added as an allowed reader type in steps.<<EBCDIC_WRITER>>was added as an allowed writer type in steps.In the same way as the flat file readers, in the reader, the
filetag contains the bean which will hold the values parsed from the input file.In the same way as the flat file readers and writers, the reader input file must be supplied as an input pin and the writer output file must be supplied as an output pin.
The copybook location must be supplied as an extra input pin. Hence an EBCDIC reader will have two input pins: the first one is the input file, the second one is the copybook, and an EBCDIC writer will have an input pin and an output pin.
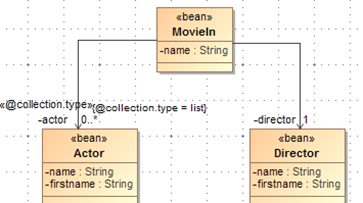
In the copybook, the record format may contain field groups. In this case, the target bean must have associations to other beans to reflect the format. The field group may even reflect a list of sub beans if
occurs > 1.
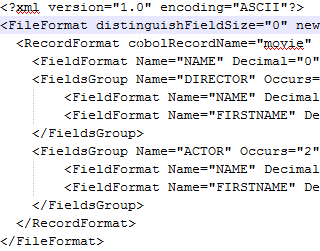
In the copybook, there may be several record formats for polymorphic data. In this case, the
filetag must contain several values.In this case, all the involved beans must bear the
<<Discriminator>>stereotype with the regex tag reflecting thedistinguishFieldValuein the copybook.
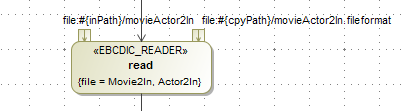

The used beans must be in the EPM layer, because of a dependency on the EBCDIC specific framework. However, depending on where the framework is dispatched, this constraint might be lifted.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Decomposition mechanism of BAGS expressions failed when index accesses concern item modeled with the “List” type and “Template Object” stereotype.
Transmodelling of
PERFORM VARYINGstatement was wrong. TheWHILEpattern, from the transmodelling, used a boolean condition, from theUNTILCobol Clause, which has to be negated.The SCL/JCP Annotation Editor is available again.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Lombok annotations were changed in the generated code. Now annotations
@Getterand@Setterare used instead of the@Dataannotation.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
The following COBOL construction are now properly parsed:
The NOT ON EXCEPTION and AT clauses in FIND statement.
The ON EXCEPTION clause in DELETE statement.
FUNCTION(DMERROR)
MYSELF(VALUE)
CHANGE ATTRIBUTE AREAS
The DOUBLE and BLANK features on PIC definition
The non-mandatory keyword IS in SIGN IS features on PIC definition
The RECORD feature on SEEK statement
The MOVE [A :B :C] form statement
The THRU features of RENAMES clause on data definition
The COBOL EVALUATE statement with ALSO feature is now properly transmodeled.
The nested IF Control Structures are now right after “CALL PROGRAM.” Statement.
With respect to the previous released evolution of the capability to map fields on synthetic getters and setters: the restriction of use on non-indexed access has been lifted. Thus, reading and writing access on fields can use these synthetic getters and setters as the shows the following screen shot.
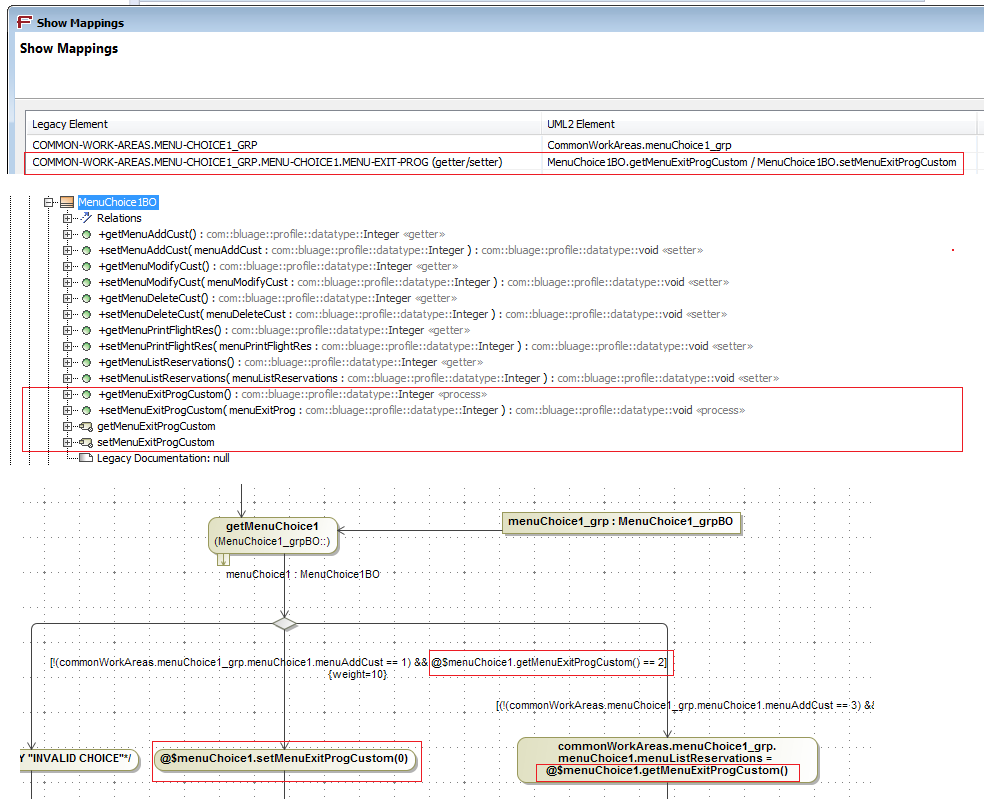
It is now possible to programmatically specify resource names to be used by a batch. This feature uses a syntax as following :
$j(var) will look up the “var” variable in the job context
$s(var) will look up the “var” variable in the step context
For instance typing file:$j(path)/$s(filename).txt in the substitution properties for an output file will enable to output in a file that will dynamically built with the values of the “path” and “filename” variables.
Note that the look up is done at bean initialization. Thus this improvement can’t be used to switch from a file to another in the middle of a processing.
In the next example, the input file is static and the output file is programmatically specified:

Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
This Spring part of product is based on Spring Framework 4.x.
Mapping on particular modernized entities was wrong and thus led to “TODO” opaque actions or invalid guard on conditions. This concerned level 01 or 77 with only level 88 entities. It was fixed.
Some wrong “Abstract::abs()” were generated in BAGS opaque action during transmodeling of a move statement from String to a signed type. In this case no conversion to absolute value is used anymore. If an incompatibility of type is detected, a warning note is added to generated UML.
Some wrong @ReverseUtils.NoName() operation were generated when transmodeling Perform XXX THRU YYY statement. It was fixed.
SET XXXX (TITLE) TO YYY statement led to exception in transmodeling step. It was fixed.
Lack of linking on entities defined from file description and database led to “TODO” opaque actions. Linking on these entities was established and solved the problem.
Specific fragments of pom.xml configuration can now be directly injected into the generated project.
A workflow property specificPomPath has been added to the com.netfective.bluage.spring.batch BSP, in order to specify the path to the text file to inject.
If the project is configured to use a Maven parent pom, the content of this file will be injected into the parent pom.xml. Otherwise, it will be injected into the pom.xml of all modules.
Only top-level configuration elements can be injected this way, which means elements available under the <project> element.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
This Spring part of product is based on Spring Framework 4.x.
Handle the ALTER statement.
Possibility to use the following keywords as data name.
SAVE
PRIOR
CLEAR
AUDITS
Handle the POINTER VALUE NULL in segment definition.
Handle the EXTERNAL keyword in File Description definition.
Handle the CHARACTERS and AFTER keywords in COPY REPLACING BY statement.
Generated warnings about Integer to String conversion in transtyping have been removed, since they are not relevant for the supported target languages.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Following the evolution made previously on the Ebcdic Readers and Writers, the Comp-1 Unisys legacy format is now correctly used by the compare feature.
A Sonar analysis was taken into account. For the Spring Batch stack, the Business Objects now have symmetric equals methods that use
getClass()instead ofinstanceof.
By default, the Spring Batch generation generates the
MYJOB-context.xmlfile under thesrc/test/resourcesfolder.This can now be changed thanks to the
generateJobContextInTestFolderoption in the launch configuration.This option is
trueby default.If set to
false, the file will be generated in thesrc/main/resourcesinstead.
A
@Cacheablestereotype is now available and can be put on operations in the model. It must be put with acacheNametagged value.The whole cache mechanics is activated thanks to the
springCachePropertyin the project launch configuration.Workflow options exist in the workflow for the global cache configuration. They will be generated in the
ehcache.xmlfile.springCacheDiskStorespringCacheUpdateCheckspringCacheMonitoringspringCacheDynamicConfig
Other workflow options exist for the configuration of all the operations marked as
@Cacheable. These workflow options come with sensible default values but can be overridden by tagged values on the@Cacheablestereotype applied on the operation. They will also be generated in theehcache.xmlfile.Only used if the operation is marked as eternal (tagged value in the applied
@Cacheablestereotype):springCacheTimeToIdleSecondsspringCacheTimeToLiveSeconds
Always used:
springCacheMaxEntriesLocalHeapspringCacheMaxEntriesLocalDiskspringCacheDiskSpoolBufferSizeMBspringCacheMemoryStoreEvictionPolicyspringCacheTransactionalMode
Other tagged values can be added on the
@Cacheablestereotype and will be used on the generated annotation in the java code:keyscondition
All these options correspond exactly to the corresponding Spring/EHCache ones. Please refer to the Spring/EHCache documentation for more information on their exact meanings.
Command line parameters can now be added when launching a Spring Batch job. They must be added as key value pairs and separated by spaces.
myKey1=myValue1 myKey2=myValue2
These parameters can be accessed through the JobContext in the model.
If the key corresponds to a key in the
SubstitutionProperties.xmlfile, the parameter will be used instead of the value in the file.
In order to allow arbitrary annotations on the generated code, a new feature was added which allows to add raw text on model elements, through the use of
headerTextstereotype and tagged value.The tagged value may be multi-line and will be printed as-is in the generated code
Pay attention that with this feature, you must provide the Fully Qualified Name for your annotations.
Such tagged values will be taken into account on Business Objects, Entity attributes, BO process operations, Service interfaces and Service process operations.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Mars (Eclipse 4.5.1);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Following the migration of the base eclipse platform to Mars, integration was done with version 18.3 of Magicdraw.
![[Warning]](common/images/admon/warning.svg) | Warning |
|---|---|
| Due to technical limitations, a supplied patch must be used on the Blu Age product if it is to be used in a continuous integration environment (Blu Age launched by a command line). |
The throws clause and the logging code can now be removed from the
processoperations in Business Objects.The new
generateLoggingInBOProcessworkflow option defaults totruebut can be set to false to remove the logging.The new
generateThrowsInBOProcessworkflow option defaults totruebut can be set to false to remove the throws clause.
The roundtrip feature was ported to the Spring Batch product. However, this functionality is deprecated. It means that while it can be used, it is provided as-is and it will not evolve anymore.
The reason is that it only works for Java opaque actions in the model, which are discouraged. Instead, BAGS language should be used, or, if there is a piece of Java code in the model, using a specific operation, thus externalizing this piece of code in a real java class (in which the roudtrip feature is useless).
A new sort operation was added in the modelization. There are now two possibilities:
Using the
SORT_STEP, a JCL sort can be emulated. This feature already existed.Using the new
sort_ebcdic_operationstereotype, a COBOL sort can be emulated (based on the copybook fields).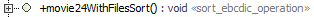
This new operation type takes two tagged values:

sort: to specify the sort rules. The fields from the copybook must be used, prefixed, withA_for ascending andD_for descending, and separated by commashasRDW: must be set totrueif the file has a record descriptor word. Defaults tofalse.
Such an operation should be used does not take an argument nor yield a result. It is typically meant to be used in a processor with no reader nor writer. It works like a
read_ebcdic_operation, followed by a sort, followed by awrite_ebcdic_operation. Thus it needs the input file, the output file and the copybook in the substitution file. Example :
Warning This feature can be used only for copybooks with only one record format. Example : 
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Mars (Eclipse 4.5.1);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
It is now possible to add a parent POM to the parent POM.

A new project type must be added in the configuration.
The name of this project type must be
pom-parent.It must bear the maven artifact id, group id and version, like other project types, and be set to skipped.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Mars (Eclipse 4.5.1);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
Bluage product is now integrated with Magicdraw 18.4. It benefits from several Magicdraw bug fixes, some of which are:
It is now possible to open a second magicdraw project and get the second containment tree.
The containment tree is now resizable.
There is no more a need to patch Bluage for continuous integration.