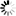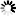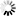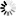Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3);
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new License Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configurations mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
The CRUD services or operations creation wizard now honor usual naming conventions (operation + entity name: “
saveCurrency”, “udateCurrency”… or service + operation + entity name). Moreover, it is not necessary to input an operation name in the operations creation wizard: the generated operation will be named operation + entity name.
lineSeparatorhas been added to template writers. It has the same behavior as on the flat file writer: thelineSeparatorOutworkflow option will be used, excepted if it is set toNO_VALUE.
The PD (Packed Decimal) sort mode is now supported. Note that the file lines must be delimited through
recordLength: CR and LF delimiters cannot be used since they may appear in a packed encoded value.
The
ebcdicDefaultValueworkflow option can now be used to control which byte if written byEbcdicEncoderwhen a value isnull. The possible values for this option areLOW_VALUE(its default),ZEROorSPACE.
It is now possible to control at runtime which copybook will be used by an EBCDIC writer. For this purpose:
A list of comma-separated copybooks must be defined in substitutions properties. Note that copybooks with different charsets are not supported.
A String parameter must be added in first position of the operation
write_ebcdic_operation. It will contain the simple name (no extension) of the copybook to use when writing.Multiple JDBC datasources in the same job can now be used. For this purpose :
A
Datasourcestereotype must be associated to aCallOperationAction(either a step reader or writer) or anInterface(service). Thedatasourcetag must contain the name of the datasource.The datasource properties are specified in the workflow, under a group property of the same name. The following properties are required:
driver,connectionUrl,usernameandpassword.
<<process>>activities can now be owned by entities. This is especially useful to model synthetic attributes through getters and setters.Order of generated artifacts for entities now follow Java standards: attribute definitions, constructors, then alternate getter and setter for each attributes.
Unneeded fully qualified names in context casts have been removed.
Duplicated constants in
EbcdicDecodedandEbcdicEncoderhave been factored.
Global Notes:
5.X products are parts of the “Blu Age II – Legacy to cloud” product family, built on Kepler (Eclipse 4.3) ;
Product documentation is available at http://wikimod.bluage.com/mediawiki/index.php/Main_Page ;
Starting with version 5.0, a new license management has been introduced, requiring the use of a new Licence Server (shipped separately – see corresponding documentation for details);
5.X versions rely on the launch configuration mechanism introduced with the 4.X product series in replacement of the previous workflow mechanism. Migrating from the 3.X workflow to the 5.X launch configuration is described in a dedicated guide.
The
hasrdwproperty of the<<ebcdic_read_operation>>is now generated at the right place.
The value of
clientModeandfileTypeproperties of theFTP_PUT_STEPstereotype is now correctly handled.
The behaviour regarding GDG numbering is as follows :
If a GDG file does not exist and n<=0, a warning is logged. There is no immediate error as it would stop the use of
<<STEP_EMPTY_FILE_CHECK>>. The reader will send itself an exception when opening the referenced file.If there is no file, the version 0 of the file is considered as
G9999V00, so that the version +1 (so the first created file) will beG0000V00.
Accesses to boolean properties BAGS are now using the
isXXXmethod when present.The
PreparedStatementare now correctly released in case of an exception.
StringUtils#substringBefore,StringUtils#substringAfterandStringUtils#stripEndutilities have been added to the UML profile.The
BigDecimalUtils#subtractutility has been added to the UML profile. It is still possible to generate the «substract» method when setting the option of «donotGenerateDeprecatedOperations» workflow tofalse.
A new "
useDatabase" workflow option has been created. It istrueby default (unchanged behaviour). In the case of a job that does not require an interaction with the database, the option can be set to false in order to avoid to specify connection information in the launch config.
It is now possible to generate a job only consisting of a
<<FTP_PUT_STEP>>step.It is now possible to generate a step only consisting of a sorting step.
It is now possible to generate a job consisting of two
<<FTP_PUT_STEP>>steps.
A
gdg-optionsproperty allows to specify the maximum number of generation for a GDG file. Each file is identified by its simple name followed by the string «(*)» and its extension (example: "file(*).txt"), then by two parameters : the limit (maximum number of generations in the dataset) and the mode (empty/noempty). The limit by default is 0 (in which case, all files are kept); the mode by default isnoempty(see below).For example:
limit=10,mode=noemptyIn this case, if the dataset has already 10 versions and we have to create a new one, we delete the oldest one.limit=10,mode=emptyIn this case, if the dataset has already 10 versions and we have to create a new one, we delete all previous versions.
When generating BAGS expressions in an activity diagram handled by a BO or an entity, « this » and its attributes (even the inherited ones) are now referenced.
The compare feature is now accessible via an Eclipse launch configuration.
This launch mode is recommended over the previous comparison wizard that will be gradually depreciated.
EBCDIC, Database and FlatFile comparisons are available.
For all cases (Ebcdic, FlatFile, BDD), the comparison project is based on a fixed structure that has to be filled out by the user before any comparison. This structure is as follows:
Copybooks: must contain all Copybooks, mandatory for the Ebcdic comparison.
Expected: contains all Ebcdic or FlatFile files to be compared.
Output: contains all current Ebcdic or FlatFile files to be compared.
Specific: must contain all substitution files.
Driver: must contain the drivers required for database comparison.
Db/views: must contain BDD views.
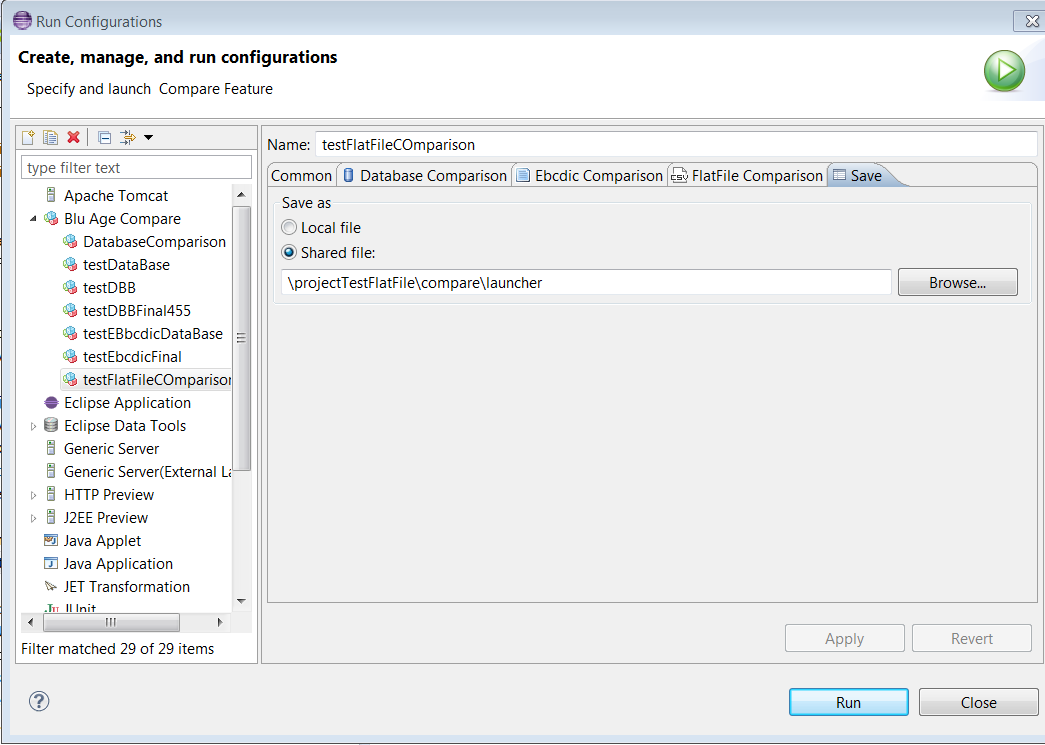
The
Outputdirectory is optional, it is here by convenience. The output directory can be anywhere, its location has to be specified in the launch configuration (see screenshots below).The launch Configuration consists of 5 tabs: Common, Database Comparison, Ebcdic Comparison, FlatFile Comparison and Save.
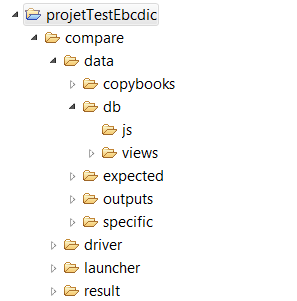
The
Commontab contains all common properties of the comparisons. The name and the type of the comparison project must be entered : Ebcdic, Database, FlatFile :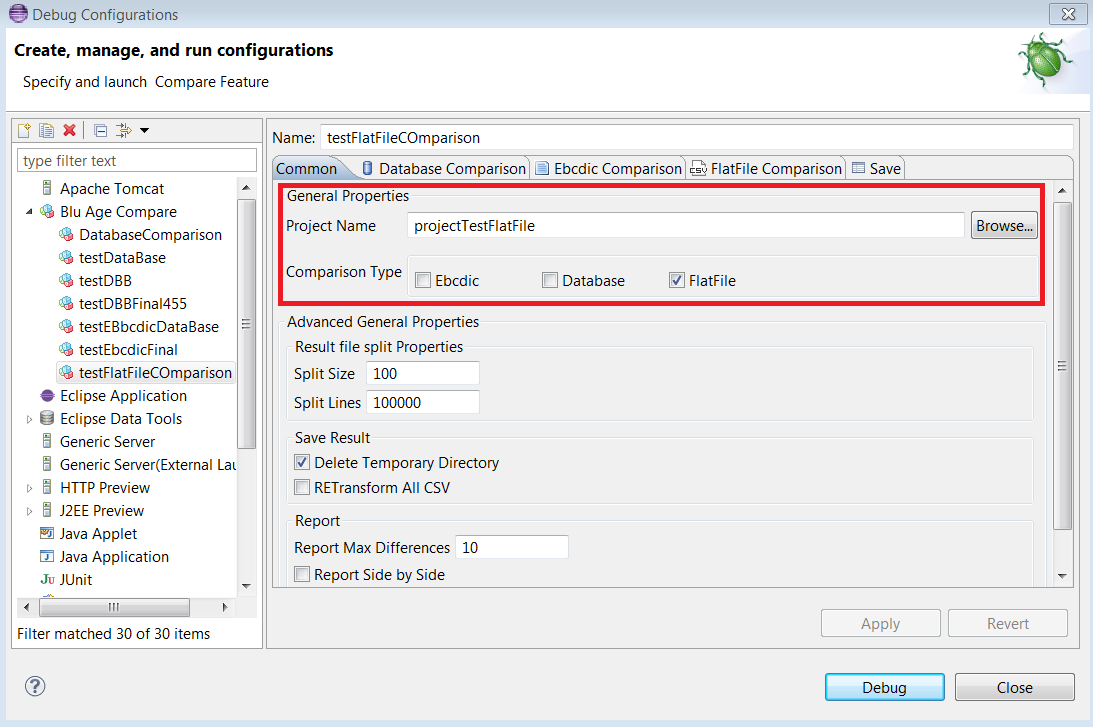
The
Database Comparisontab allows to enter the required properties when comparing BDD (see the following example).
The
EBCDIC Comparisontab allows entering required properties for an Ebcdic comparison. The user must fill in the name of Ebcdic files directory that he wants to compare (see the following example).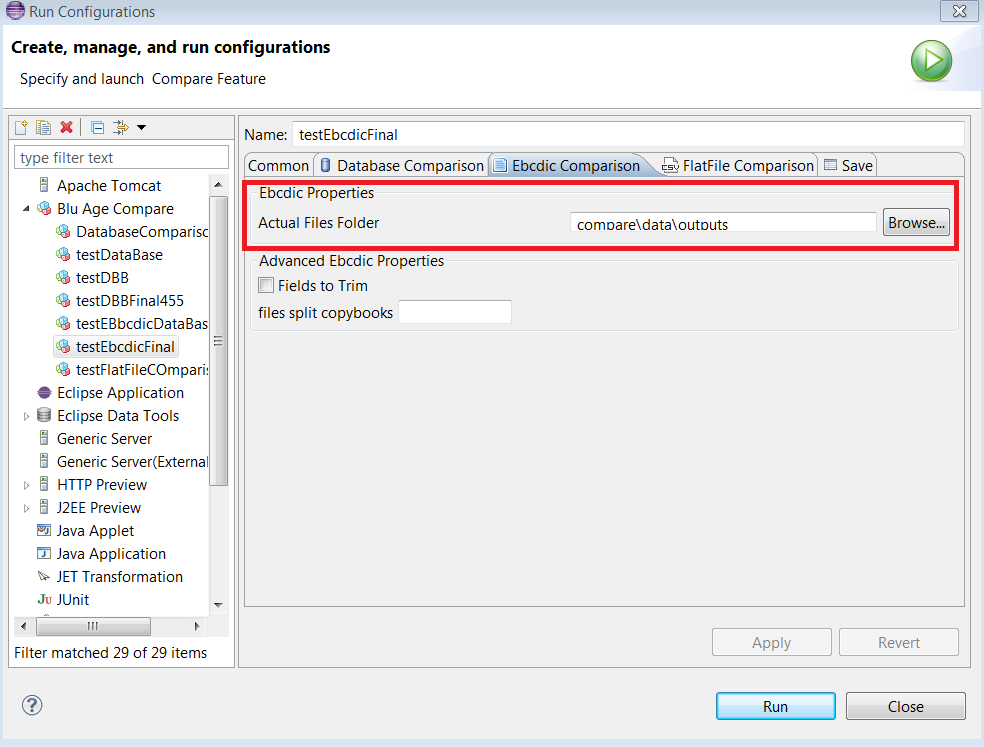
The
FlatFile Comparisontab allows to enter the required properties for a FlatFile comparison. The user must fill in the FlatFile files directory that he wants to compare (see the following example).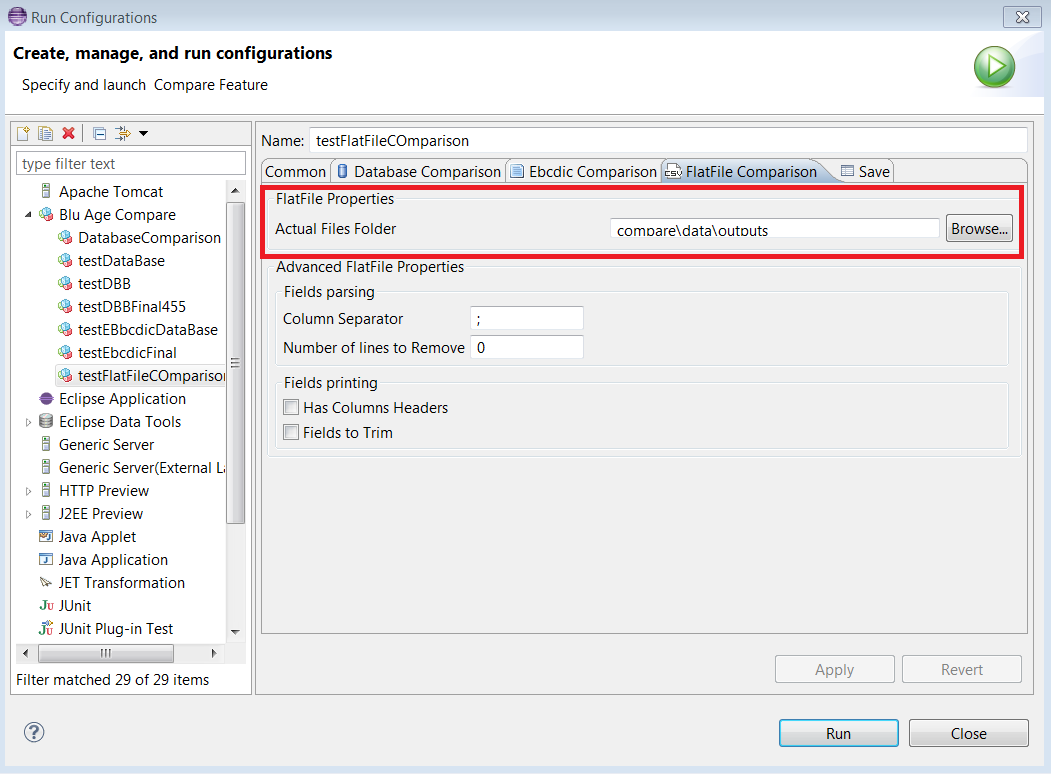
The
Savetab saves the settings in the project (see the following example).